LLM Large Language Model Cost Analysis
Introduction
The landscape of generative models is rapidly changing. The recent releases in LLM architecture models include the GPT-4 model from OpenAI and the open-source Llama2 from MetaAI.
For AI practitioners, one of the key factors beyond all criteria when choosing the right solution for their business is the cost of integrating LLM applications. There are two primary options for developing an LLM application:
- API Access Solution: Utilizing closed-source models such as the latest GPT-4 model from OpenAI via API access.
- On-Premises Solution: Building a model based on a pre-trained open-source model and hosting it within your own IT infrastructure.
In this article, we aim to address the following questions: What are the different components contributing to the cost of an LLM application, and how do they differ between each choice of approach? We will break down the cost into three parts as follows:
- Cost of Project Setup and Inference.
- Cost of Maintenance.
- Other Associated Costs.
Finally, we will present a hypothetical scenario based on one of our projects to compare the costs between API access solutions (such as ChatGPT) and open-source LLM.
Cost of initial set-up and inference:
The cost of the initial setup includes the expenses associated with storing the model and making predictions for query requests.
For the API access solution:
We have listed the three most commonly used providers (OpenAI, Cohere, Vertex AI) for an API access solution. Each provider has different pricing metrics, which depend on the specific use case (summarization, classification, embedding, etc.) and the chosen model. For each request, you are billed based on the total number of input tokens (cost for input) and generated output tokens (cost for output). In some use cases, you may also need to pay a price per request (cost per request). For example, the classification task with Cohere models costs $0.2 for every 1,000 classifications.
For the on-premise solution:
Hosting an open-source model can be challenging for your IT infrastructure due to the enormous size of model parameters. The cost of the initial setup primarily involves the expenses associated with establishing a suitable IT infrastructure to host the model.
As we can observe, the models can be categorized into two groups:
- Small-sized models that are suitable for running locally on your personal computers (~ 7B parameters).
- Large-sized models that require hosting on cloud servers such as AWS, Google Cloud Platform, or your internal GPU server.
Pricing in this context is determined by the hardware, and users are billed on an hourly basis. The cost varies, with the most affordable option being $0.6 per hour for a NVIDIA T4 (14GB) and the highest costing $45.0 per hour for 8 NVIDIA A100 GPUs (640GB).
Cost of Maintenance:
When the model’s performance decreases due to changes in data distribution, it becomes necessary to fine-tune your model using new customer datasets. Consequently, the cost of maintenance encompasses expenses related to labeling your training dataset, fine-tuning, and deploying a new model.
For the API Access Solution:
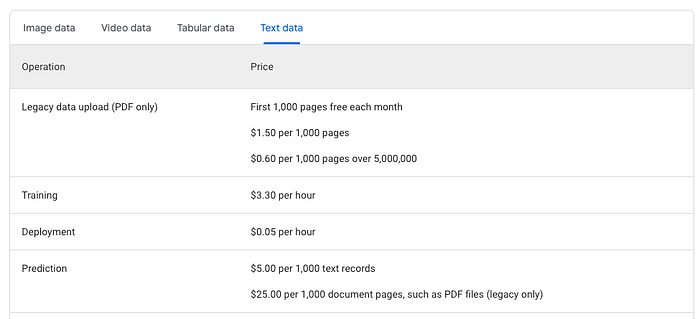
Some providers, such as OpenAI and VertexAI, offer a fine-tuning service with their pricing that covers data upload, model training, and deployment of the newly trained model. Below is an example of a pricing matrix for ChatGPT by OpenAI and Vertex AI:

For the on-premise solution:
The cost of fine-tuning open-source models primarily consists of expenses related to running the IT infrastructure for retraining a Language Model (LM). The cost you incur is directly proportional to the duration for which you rent the server to fine-tune the model. The necessary time to complete the fine-tuning can be estimated based on the complexity of the task, such as the size of your pre-trained model (number of model parameters), the size of the training dataset (number of tokens), and the training procedure (number of batches, number of epochs). The more complex the task, the longer it will take.
For example, fine-tuning the smaller model Falcon 7B may require a machine with at least twice the memory capacity (approximately 16GB). For a training dataset containing several thousand tokens, it can take about a day to complete the fine-tuning. The total cost can be calculated as follows:
Total Cost = Hourly cost of the rented instance x Number of hours required for training the model.
Other Considerations:
Additional costs to consider include environmental factors such as CO2 emissions and human resources.
CO2 Emissions:
AI model sizes are doubling every 3.4 months, leading to a more significant environmental footprint for deep-learning models due to their increasing size. In one study, it was estimated that OpenAI’s GPT-3 emits more than 500 metric tons of CO2 during training:
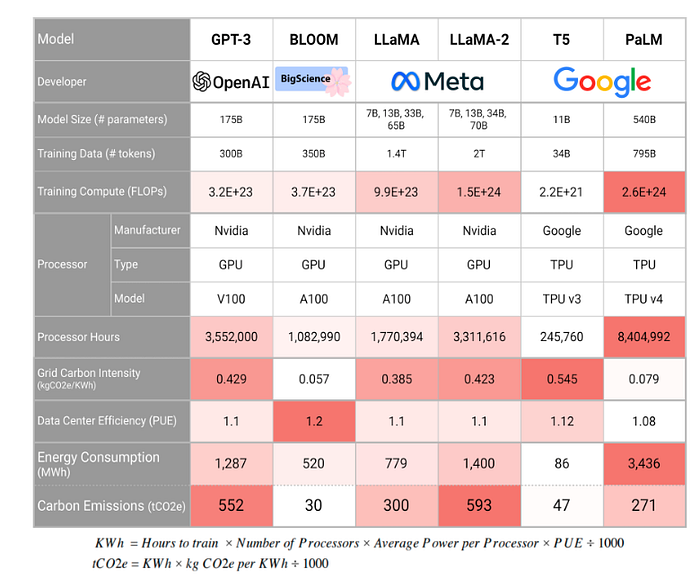
As we can see, the carbon emission cost for training LLMs is generally high. However, it can be amortized through a large scale of use and the replacement of economic activities by LLMs.
When it comes to using LLMs for inference or retraining, AI practitioners need to carefully choose an adaptive IT infrastructure to reduce the CO2 cost. Several important factors determine the level of CO2 impact when using an IT infrastructure:
- Compute: This is the number of FLOPs (floating point operations per second) needed to complete a task. It depends on model parameters and data size. Some studies show that a larger model doesn’t always result in better performance. You can choose a model that fits your use case well by striking a balance between model size and performance.
- Data Center Location and Efficiency: Each data center is powered by local energy production, so CO2 emissions and energy efficiency vary based on the data center’s location.
- Hardware: Different computing processors (CPUs, GPUs, TPUs) have varying energy efficiencies for specific tasks.
In real-life situations, we can estimate the impact of CO2 emissions directly through the overall energy or resource consumption by the IT infrastructure hosting the LLM applications. One useful tool for tracking CO2 consumption is CodeCarbon.io .
Expertise:
Another critical resource to pay attention to is the human factor. How well the team can acquire the new knowledge and skills required to maintain the service is vital. In this regard, open-source solutions tend to be more costly because they require a specialized staff to train and maintain LLM models. Conversely, for API access solutions, these tasks can be handled by the provider’s engineering team.
Cost Comparison between ChatGPT and Open-Source LLM:
As discussed in the previous sections, the cost of implementing an LLM project varies depending on the chosen solution and the specific task. In this section, we aim to provide an estimation of costs based on the configuration of one of our projects.
Let’s consider that we want to build an API for a chatbot application powered by LLM technology. Assume that, on average, we have 50 chat discussions per day, with each discussion containing about 1000 words, including both the questions and answers.
Therefore, the total number of tokens used per day is calculated as 1000 x 50 x 3/4 = 37,500 tokens per day (we assume that one token is equivalent to about 3/4 of a word for the English language). The cost for using GPT-3.5 at a rate of $0.02 per token is $0.75 per day or 270$ per year.
If the request volume were to escalate to X times its current level, the cost would also increase linearly to X times. For instance, based on the rule of thumb, if the number of chats inscreased to 500 chats/ day the annual cost would increase to 2,7$ and for 5K chats per day, the annual cost would inscrease to 27K$.
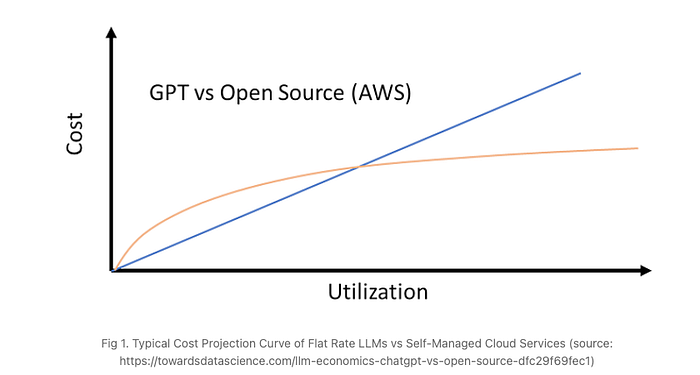
On the other hand, for an on-premise solution, if the number of requests increases, we need to allocate a larger IT infrastructure to ensure optimal latency. However, the augmentation is certainly less than a linear augmentation for an API solution.
Consequently, there is a usage threshold at which ChatGPT is more cost-effective than utilizing open-source LLMs deployed to AWS when the number of requests is not high and remains below the break-even point. Indeed, the property of cost scaling with usage can also apply to the cost of maintenance, specifically fine-tuning, when dealing with very large dataset sizes.
Final Thoughts:
In this post, we discussed the key differences between two approaches: 3rd-party solutions vs. open-source solutions, and how to estimate the total cost using an example project. Third party solution offers convenience and scalability but may result in higher expenses for inference. On the other hand, on-premises deployment provides greater control over data privacy but demands meticulous infrastructure and resource management.
The cost structure in this field could undergo rapid changes in the near future. It’s important to note that the estimations are rough, as there can be additional factors when running the entire pipeline in real-life scenario. To obtain more accurate insights, it is advisable to conduct benchmark projects, such as Proof of Concept (POC) projects, to estimate the average cost of the entire project pipeline.
Certain techniques can be applied to reduce costs, especially for strategies that tend to become expensive when dealing with large collections of queries and texts.
FrugalGPT: this technique has the capability to significantly reduce inference costs, up to 98%, while outperforming even the best individual LLMs (like GPT-4). There are three main strategies:
- Prompt Adaptation: This strategy explores ways to identify effective, often shorter prompts to reduce costs.
- LLM Approximation: It aims to create simpler and more cost-effective LLMs that can match the performance of powerful yet expensive LLMs on specific tasks.
- LLM Cascade: This strategy focuses on adaptively choosing which LLM APIs to use for different queries.
Quantized Model: relates to techniques for reducing the precision of model weights, which can significantly decrease memory and computational demands during the inference stage.
Aknowledgements
Thanks to our colleagues Agnès GIRARDOT, Laura RIANO BERMUDEZ, Lu WANG and Jean-Baptiste BARDIN for the article review.
About the Author
Alexandre DO is a senior Data Scientist at La Javaness and has conducted many R&D projects on NLP applications and interested in ESG topics.